본 포스팅에서는 python으로 엑셀을 읽는 법과 저장하는 법에 대해 얘기하고자 한다.
pandas.read
다음과 같이 name, dcm_paths, label_paths, dcm_extentions, label_extentions의 열들을 가지는 xlsx 파일을 읽어보자.

pandas는 보통 pd로 줄여서 통용된다.
"pd.read_excel('엑셀파일명')"을 사용하면 쉽게 파일을 읽을 수 있다.
import pandas as pd
excel_path = './annotation.xlsx'
df = pd.read_excel(excel_path)
df
위 예제와 같이 pd.read_excel로 읽어들이면 DataFrame 형태로 반환해 주는데 여기서 DataFrame이란 pandas에서 제공해주는 데이터가 행렬로 구성되는 2차원 형식이라고 보면 된다.
읽어드린 데이터프레임은 "df" 변수로 선언되었는데 이를 그대로 출력시켜보면 다음과 같이 알아서 이쁘게 표로 출력된다.
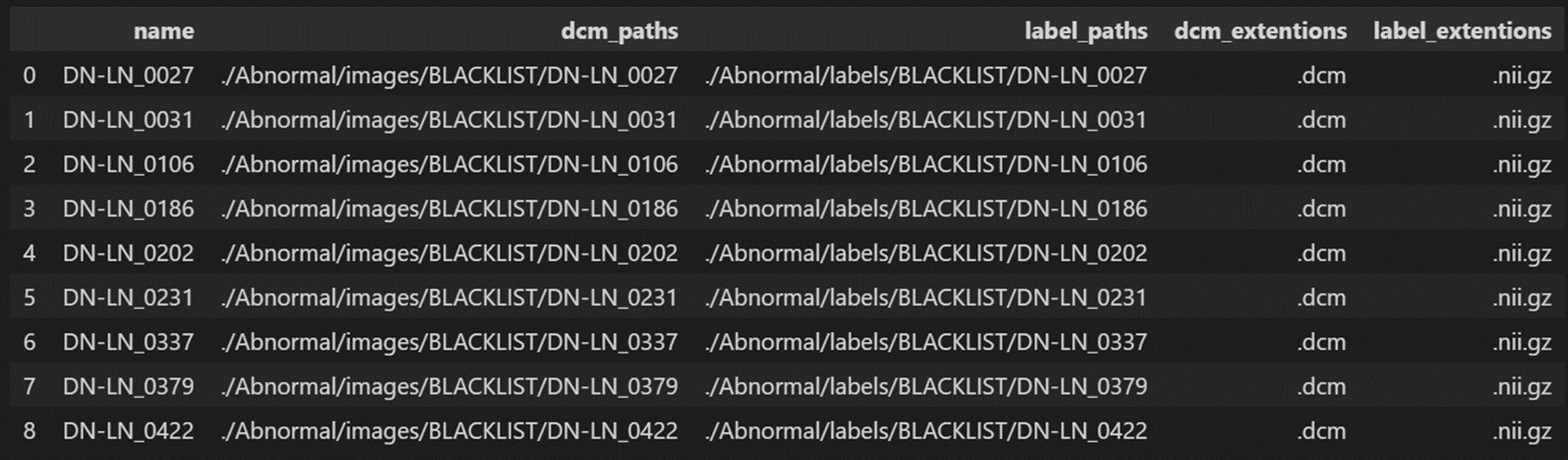
특정 열을 출력하고 싶다면 데이터 프레임을 dictionary 형식의 데이터를 다루듯이 키를 입력하고 .values를 추가하면 값들만 추출할 수 있다.
name = df['name'].values
dcm_paths = df['dcm_paths'].values
print('name:', name)
# name: ['DN-LN_0027' 'DN-LN_0031' 'DN-LN_0106' 'DN-LN_0186' 'DN-LN_0202' 'DN-LN_0231' 'DN-LN_0337' 'DN-LN_0379' 'DN-LN_0422']
print('dcm_paths:', dcm_paths)
# dcm_paths: ['./Abnormal/images/BLACKLIST/DN-LN_0027' './Abnormal/images/BLACKLIST/DN-LN_0031' './Abnormal/images/BLACKLIST/DN-LN_0106' './Abnormal/images/BLACKLIST/DN-LN_0186' './Abnormal/images/BLACKLIST/DN-LN_0202' './Abnormal/images/BLACKLIST/DN-LN_0231' './Abnormal/images/BLACKLIST/DN-LN_0337' './Abnormal/images/BLACKLIST/DN-LN_0379' './Abnormal/images/BLACKLIST/DN-LN_0422']
dataframe.to_excel
이제는 반대로 엑셀로 데이터를 저장해보자.
위 예제에서 dataframe을 dictionary 형태로 다뤘듯이 우선 dictionary 형태로 데이터를 구성해 주자.
new_dict = {}
new_dict['name'] = ['xray_1', 'xray_2']
new_dict['dcm_paths'] = ['./Abnormal/images/xray/1', './Abnormal/images/xray/2']
new_dict['label_paths'] = ['./Abnormal/labels/xray/1', './Abnormal/labels/xray/2']
new_dict['dcm_extentions'] = ['.dcm', '.dcm']
new_dict['label_extentions'] = ['.png', '.png']
대괄호를 통해 빈 dict을 구성해 주고 열이 될 단어들을 key에 순서대로 각 셀에 입력될 내용들을 value에 넣어주자.
print(new_dict)
"""
{'name': ['xray_1', 'xray_2'],
'dcm_paths': ['./Abnormal/images/xray/1', './Abnormal/images/xray/2'],
'label_paths': ['./Abnormal/labels/xray/1', './Abnormal/labels/xray/2'],
'dcm_extentions': ['.dcm', '.dcm'], 'label_extentions': ['.png', '.png']}
"""
이후 이 dictionary인 변수를 pandas.DataFrame으로 감싸주어 데이터 프레임 형식으로 변환시켜 주자.
new_df = pd.DataFrame(new_dict)
new_df
이렇게 변환된 데이터 프레임에 ".to_excel('원하는경로와 파일명')"을 추가하여 저장시키면 된다.
new_df.to_excel('./new_annotation.xlsx')
저장된 파일을 열어보자.

추가적으로 저 A열에 숫자들은 자동으로 인덱싱 되어 추가되는데 이를 추가하지 않고 저장하기 위해서는 "index=False"를 추가하면 된다.
new_df.to_excel('./new_annotation.xlsx',index=False)
'Python > Pandas' 카테고리의 다른 글
| [Python] Pandas를 활용하여 xls 파일 읽기 (0) | 2023.02.09 |
|---|---|
| [Python] Pandas로 암호화된 엑셀 파일 읽기 (0) | 2023.02.09 |
| [Python] Pandas와 for 문으로 엑셀 데이터 밑으로 붙이기 (0) | 2023.02.04 |
| [Python] pandas로 xlsx 파일과 csv 파일 읽기 (0) | 2023.02.02 |




댓글